Quantifying Clipping Softness
We present a formal description of clipping functions and a method to analyze their softness mostly audio applications (guitar electronics, audio DSP, etc.) in mind. We also present the softest clipping function, the Blunter, and report the results of an experiment showing that it is indeed the softest function given our description of clipping softness.
Introduction
Clipping is a fundamental concept in signal processing. In high fidelity applications it may be an undesirable artifact of limited headroom and/or failed gain staging, but it can also be an intentional creative effect like in guitar electronics or some music production gear. Either way, the clipping softness has major implications how it is perceived.
There are multiple studies about non-linear distortions in audio that include some analysis of hard and soft clippers. Some focus on detecting these kinds of distortions12, others focus on how these distortions are perceived134. However, these studies only use soft clippers as a part of their study, which is not directly about softness. In other words, these studies have not studied clipping softness itself in detail.
Hard clipping is commonly described as follows: once a signal reaches some threshold it cannot exceed that threshold and will be abruptly cut as shown in Figure 1 (a). There is not much ambiguity regarding to this type of clipping. A soft clipper, on the other hand, is commonly described as a type of clipping where the signal level may keep increasing after the threshold is reached when increasing the input signal level as shown in Figure 1 (b). However, there are few ambiguities in this definition of soft clipping: the threshold of clipping, the upper limit of clipping, and how the signal transforms from the threshold to to the limit. Many clippers do not have a well defined threshold nor they have a well defined limit like
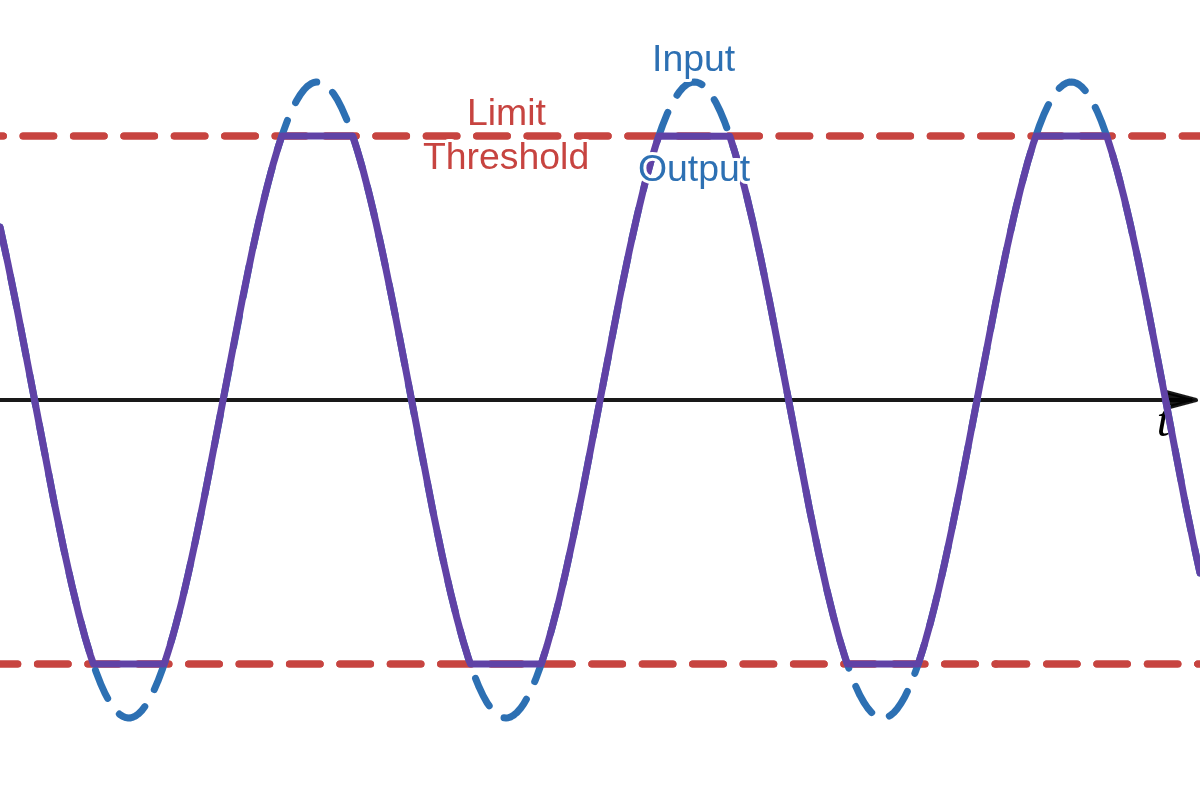 (a) Hard clipping
(a) Hard clipping
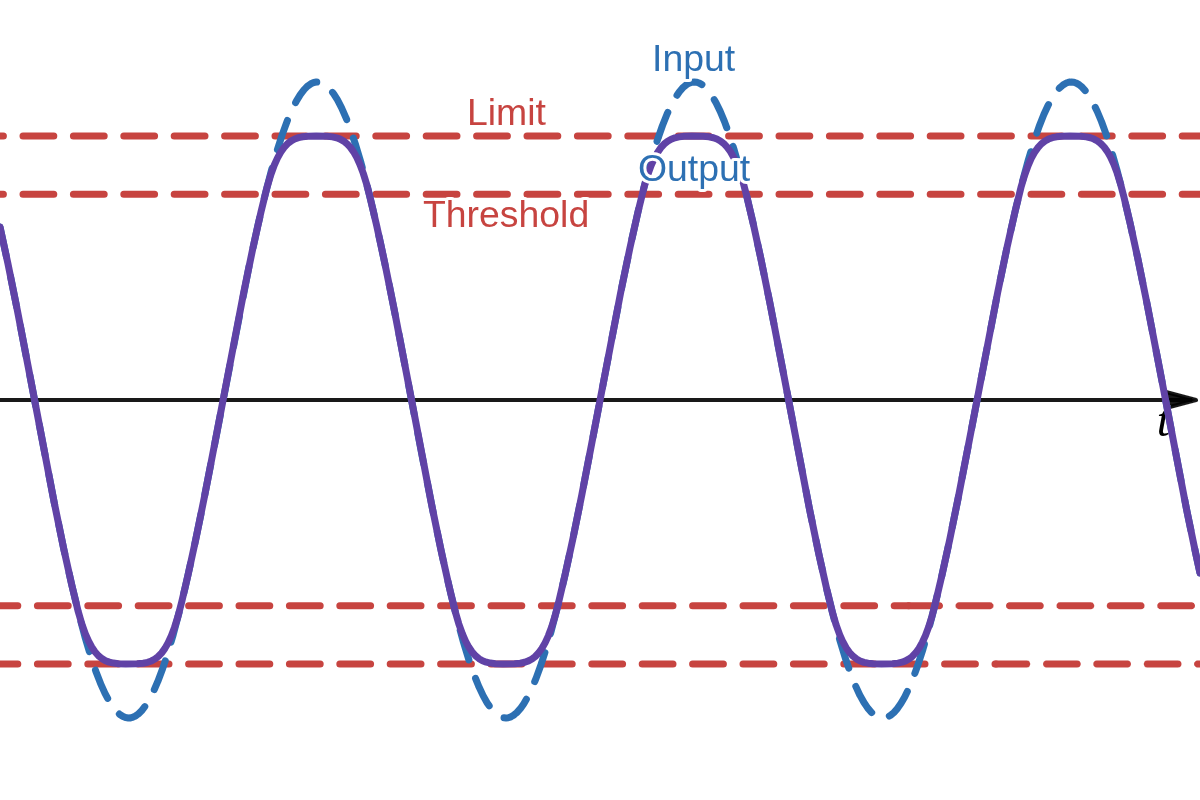 (b) Soft clipping
(b) Soft clipping
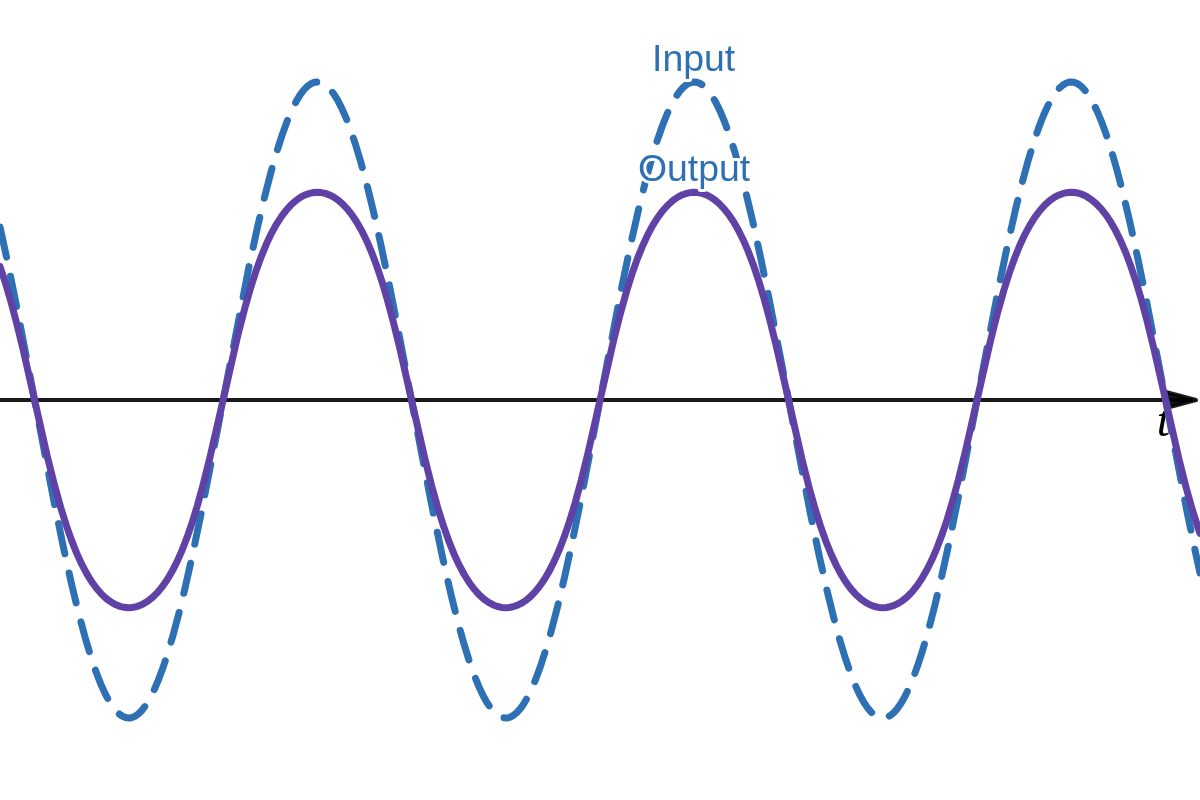 (c) Arctan soft clipping
(c) Arctan soft clipping
Furthermore, the value for the hypothetical threshold and limit changes as the gain of the input signal changes and/or the gain of the output signal changes. All real world systems have these parameters, often given by the designer (like guitar amplifier gain and volume controls) of the system, but sometimes they are implicit to the system. For example, an implicit output gain could be given by the choice of components in an electronic circuit and implicit input gain could be given by the loudness of a singer singing into a microphone. This leads to yet another question: how would you compare the clipping softness of systems with varying input and output gain characteristics?
Our model deals with the threshold and limit ambiguities by analyzing the second derivative of the clipping functions instead of analyzing some hypothetical thresholds and limits. The second derivative describes exactly how abruptly the changes in the input signal change with increasing input signal levels. We will also look at an alternative definition of softness based on change of higher order harmonics as input amplitude increases and present methods to normalize input and output gains to enable meaningful comparison of different clipper functions.
But before anything, we perform a quick review of any relevant background information. The reader is assumed to have some understanding about these topics, but the main purpose of the review is to frame the information in a way that suits our problem.
Background Review
A periodic signal
where
Clipping a pure sinusoid generates harmonics. A common way of measuring overall distortion of a system is to feed a sinusoid to it and measure the amplitudes of the generated harmonics relative to the fundamental. This is known as THD (total harmonic distortion), and it can be computed using the Fourier coefficients like so:
Definitions
Clipping Function
A clipping function
For any meaningful analysis the clipping function must be normalized. For any clipping function
where
Clippers can be categorized in three categories:
Bounded clippers cannot increase their output once some limit is reached. In other words, bounded clippers are piece-wise functions that have zero derivative beyond any given signal level limit.
Converging clippers have a limit when signal level approaches infinity.
Diverging clippers do not converge. Output signal level can be increased indefinitely.
Asymmetric clippers can be any combination of these categories for each side of the waveform.
Real-world clippers seen in music production gear often have a non-flat frequency response and non-zero phase response5. This complicates any attempts to analyze softness significantly: any results will be frequency dependent. However, analyzing the non-linearities isolated from any linear effects is often preferred anyway for meaningful comparisons. Measuring a hard clipper processed with a steep low pass filter to be softer than a soft clipper processed with a high pass filter doesn't seem like a very useful result. Therefore, we will be assuming flat frequency response and zero phase if not stated otherwise.
Hardness and Softness
Clipping hardness
The maximum absolute value of the second derivate describes how abruptly the change of a signal changes. It is analogous to acceleration in kinematics. We only care about it's magnitude. Using
If
which allows us to determine hardness in terms of unnormalized clippers like so:
While
WTHD Hardness
The THD is not a good measure of how distorted an audio signal is perceived to be. For example, it completely ignores the fact that higher order harmonics are perceived more strongly and offensively4. A simple heuristic to accommodate for the perception of the higher order harmonics is to weight the harmonics' amplitudes linearly. We define weighted total harmonic distortion (WTHD) to be
If we feed a sinusoid to a clipper, as the input amplitude of the input sinusoid changes, so does the the Fourier coefficients, and thus the WTHD as well. So the WTHD of a clipper can be described as a function of input amplitude:
where
are the Fourier coefficients produced by feeding a sinusoid to
Since hardness is supposed to measure how the signal changes, we can use the derivative of
This potentially more accurately would match the perception of softness. By measuring the change in WTHD, we are measuring how the clipping "feels". For example, an electric guitar player playing trough a hard clipper with low input gain might note that playing softly enough results in no distortion and playing harder immediately produces noticeable higher order harmonics.
The problem with this definition is that computing it for arbitrary functions would require computing the Fourier series repeatedly and observing how the WTHD changes. This could be computationally very expensive, so we will focus on the second derivative based definition instead. However, we will see later that the second derivative based and the WTHD based definitions are related to each other.
Note that
We will be referring to non-WTHD (second derivative based) hardness as just hardness, WTHD is explicitly stated when referring to WTHD hardness from now on.
Hard Clipper and Quadratic Soft Clipper
Our model is already powerful enough to do analysis of hard clipper
A hard clipper is not differentiable, and thus, not a valid clipping function on it's own. However, we can approximate it using a quadratic soft clipper
It is trivial to see that the maximum of the second derivative of the soft clipper is completely determined by the spline. We can also see that
so the hardness of
which seems rather intuitive. A similar reasoning can probably be applied to observe that
The analysis for negative side would be identical of course. However, it should be noted that asymmetrical hard clipping will always have a softness of zero, regardless of clipping thresholds of either side. In fact, the other side may not be clipped at all and the result is still zero. This may seem confusing and like it could undermine the usefulness of the model. And indeed, fully asymmetrical (one side linear) clipping will have a very distinct sound from symmetrical clipping. However, both asymmetrical and symmetrical hard clipping have an important property: once a threshold is reached (doesn't matter which one or both), the sound is immediately notably distorted. The abruptness of the clipping is what softness is measuring, a complete description of tonal characteristics of any given clipping function is outside of the scope of this study.
While we only needed to consider simplified unipolar hard clipper and soft clipper, their complete descriptions can be useful for DSP or other purposes. So for completeness, the full generic description of asymmetric hard clipper and quadratic soft clipper is as follows:
where
where
Normalization
The input gain controls the amount of clipping distortion. Input gain affects the output level, but output gain does not affect the amount of distortion, so input gain must be normalized before output gain normalization. Input gain will be normalized by setting it to a value such that measuring the THD of the clipping functions result to same normalized THD value. Again, to measure the amplitudes of the Fourier coefficients for our THD measurement, we need to pass a sinusoid to our clipper, so in our case
but once again, assuming zero phase, we get
It should also be noted that symmetric clippers will not produce any even harmonics6. This is not necessarily important for our analysis, but it is useful to know to decrease computation time when applicable.
The value of THD normalization will affect softness. Consider bounded clippers: given a periodic input, large amounts of input gain would make the output to converge to a square wave with well defined amplitude. But for diverging clippers (like
The output gain controls the overall volume. It does not change the clipping characteristics, but the hardness (the second derivative) is directly proportional to it, so it must be normalized. It will be normalized by total power of the clipping function given some signal, which is commonly described by root mean square (RMS):
The issue with RMS is that it is also affected by DC, which would affect hardness too despite being inaudible. We need to use the standard deviation
where
is the DC offset or the mean of the signal. Since the DC is inaudible but affects headroom, it is commonly filtered out before any clipping happens. Furthermore, symmetric clippers do not introduce any DC offset, so it is common to have
We must choose an input signal for the measurement. It might be tempting to use a sinusoid, since that is what we needed to use to measure and normalize input gain, but the problem with that is that real world audio is rarely just a pure sinusoid. Furthermore, passing
We need a signal that is roughly an average of all signals in some sense. A good candidate could be Gaussian noise, which has a probability mass function that follows the normal distribution. The probability mass describes how likely it is for a sample to get a specific value7. This is important for us, because we need heuristics to determine how our clipping function would transform any given input values to output values on average. Since we cannot know our input signals, a probabilistic approach seems appropriate.
Gaussian noise does have one huge issue for practical measurements: we would need to generate a huge amount of samples of it in order to converge. This could be done using any pseudo-random number generator with uniform distribution and Box-Muller transform8, but it would require huge amount of processing before it gets useful due to reliance of statistical convergence. Luckily, we don't need Gaussian noise, we just need anything that will give us a similar probability mass. It turns out that sampling the quantile function of any given distribution enough times at regular intervals will yield the corresponding probability mass9. This means that as our signal we can use the quantile function of a Gaussian called the probit function, which can be computed using
where
A great property of
The Blunter
There exists a symmetric clipper that is softer than any other symmetric clipper for a range of THD normalization values, which we will call the Blunter. We will be referring to it quite a lot, so it worth defining and naming it. The unnormalized Blunter is defined as
The normalized Blunter is
The Blunter is equivalent to our quadratic soft clipper when knee
A way to interpret the constant second derivative of the polynomial part is to imagine a peaky local extreme in the second derivative and spread it out as evenly and as widely as possible. This would mean that for any other clipper to be softer, they would have to have their extrema spread out even more evenly and widely, which should be only possible if the THD normalization value is low enough (diverging clippers are expected to be softer for high THD normalization values since they are not limited). This would mean that a hardness that is smaller than
Finding the Softest Clipper
We provide a repository10 that contains code for multiple experiments and tests for this study. The main experiment in src/smoothest.c generates all potential symmetric clipping functions with given precision BASE. For each of the generated functions, a normalized input gain and output gain is calculated to finally find the hardness of the function. Finally, the function with minimum hardness is found. Names f and f_* refer to clipping function lookup-tables.
Counter
An algorithm was developed that generates all potential symmetric clipping functions given a discrete precision of BASE. The basic idea is based on a counter: take BASE number of digits and start counting in that BASE. The generated sequence of numbers will be represent the positive side of a clipping function as a lookup table. By counting all numbers, we can ensure that each clipping function has in fact been generated. However, this naïve approach would have a time complexity of
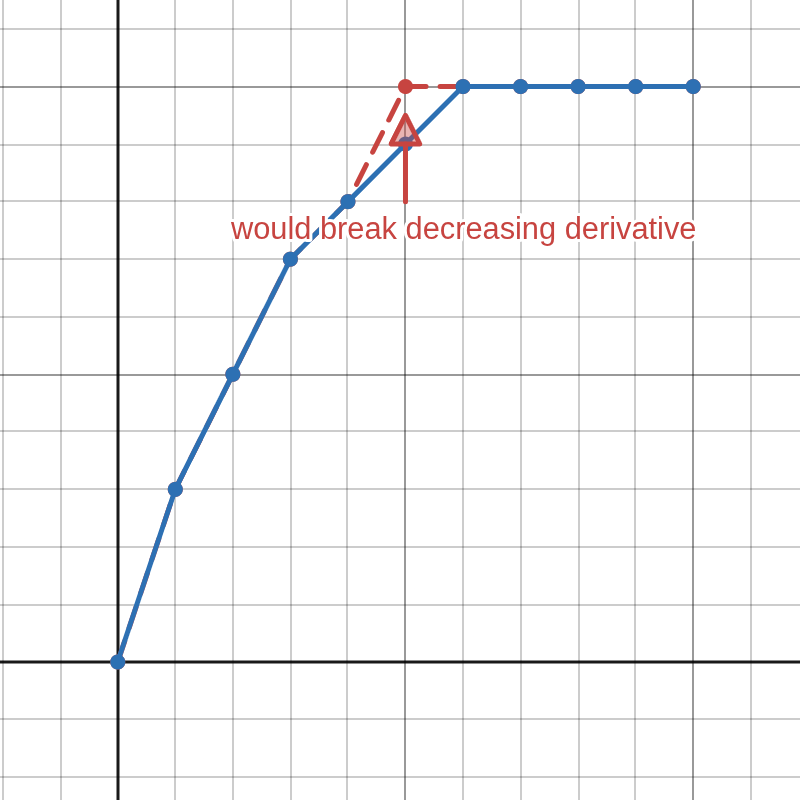
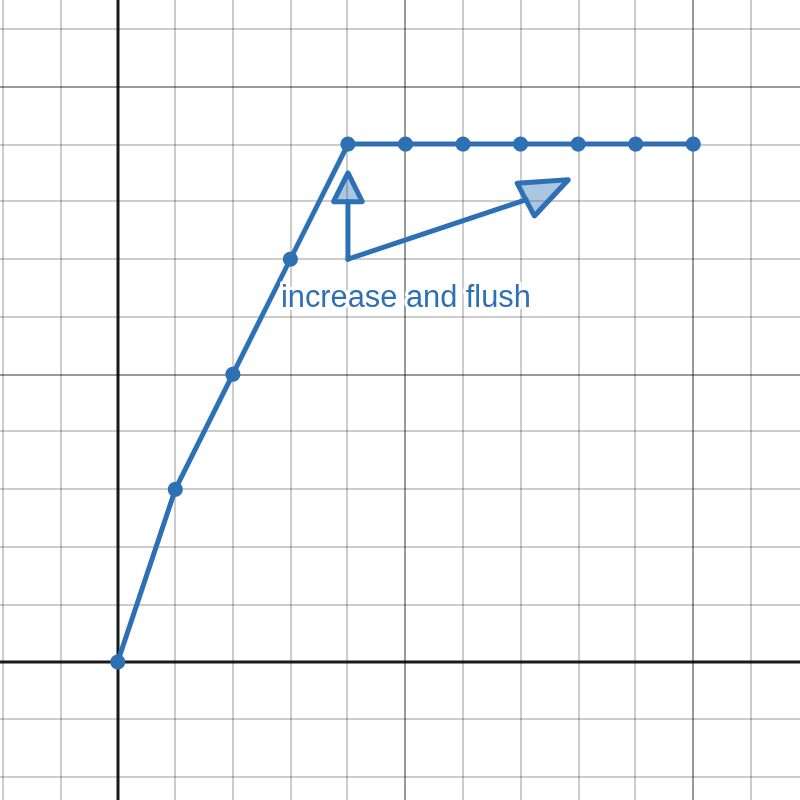
An important concept for our algorithm is flushing. It is demonstrated in Figure 2 and can be described as follows: Knowing that the first derivative of a valid clipping function must be greater than or equal to zero, each time we increment a digit in the middle to a value that is greater than the digit on it's right side, we can duplicate the incremented digit to all of the digits on the right side (flush). Of course, a real counter would only increment digits in the middle when carrying, but the concept of flushing is important for us.
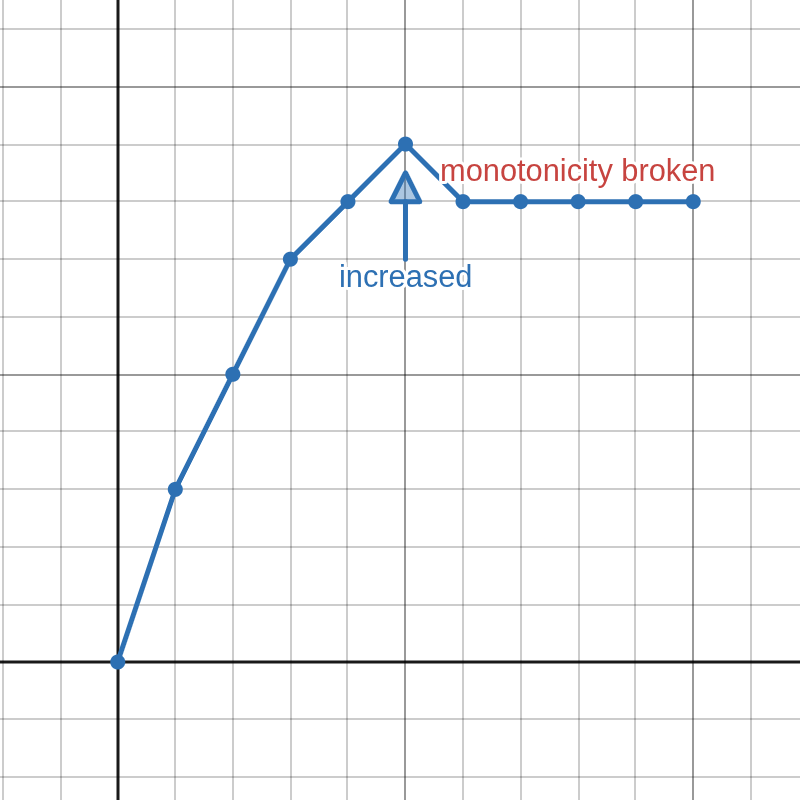 (a) Cannot increment just this one.
(a) Cannot increment just this one.
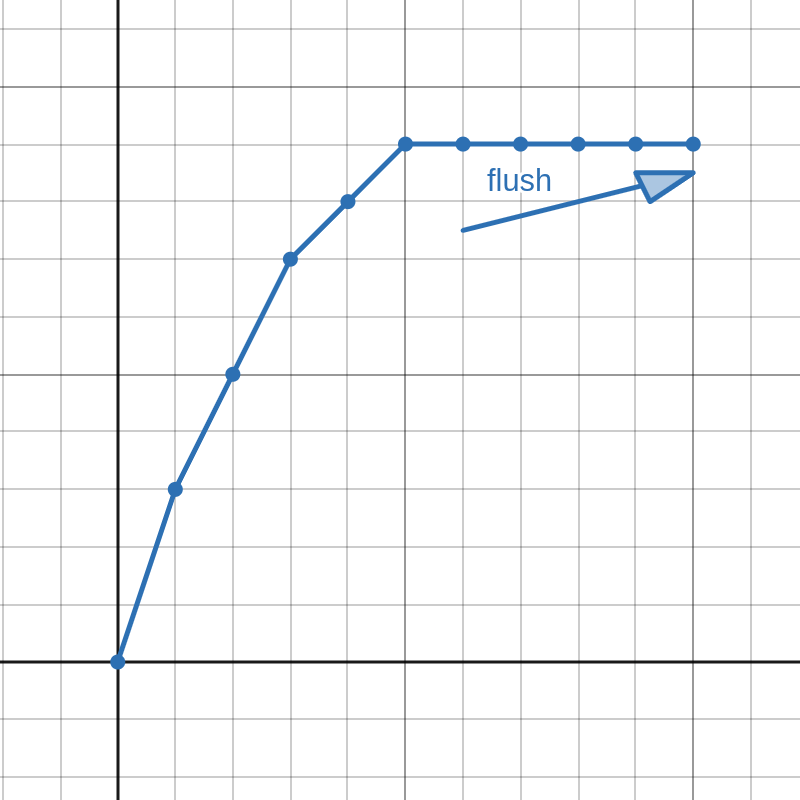 (b) Have to increment all these.
(b) Have to increment all these.
Since the counter only generates the positive side, it's output has to be duplicated to the negative side. In our implementation, the actual duplication is done later in the processing chain, but our counter has to take it into account anyway. To preserve symmetry on duplication, the digit at index zero must be fixed to zero. Also, given unimodal derivative, the derivative at index zero must be non-zero. This means that the counter must count from index one, and we count each digit from one to BASE instead of zero to BASE-1 like a regular counter. Given these constraints, our counting algorithm can be described as follows:
Initialize the counter: the digit at index zero shall be set to zero, the rest shall be set to one.
Knowing that the first derivative is unimodal, we can deduce that the first derivative is also monotonically decreasing on the positive side, so we can skip all increments from the right that would increase the derivative from zero to one. Flush from the next digit on the right of the first digit with non-zero derivative.
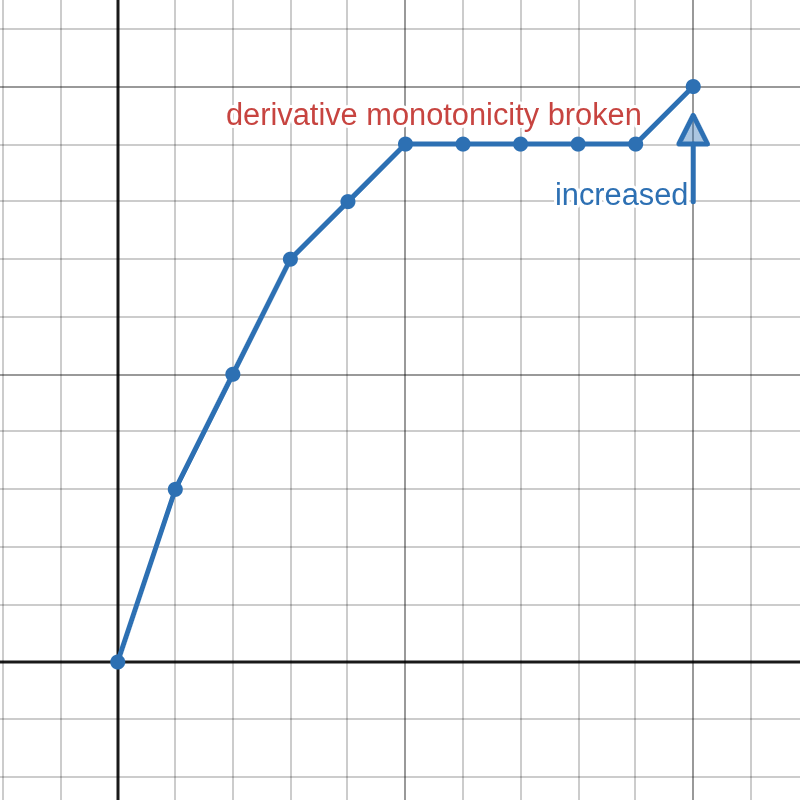 (a) Cannot increment just this one.
(a) Cannot increment just this one.
 (b) Have to increment all these.
(b) Have to increment all these.
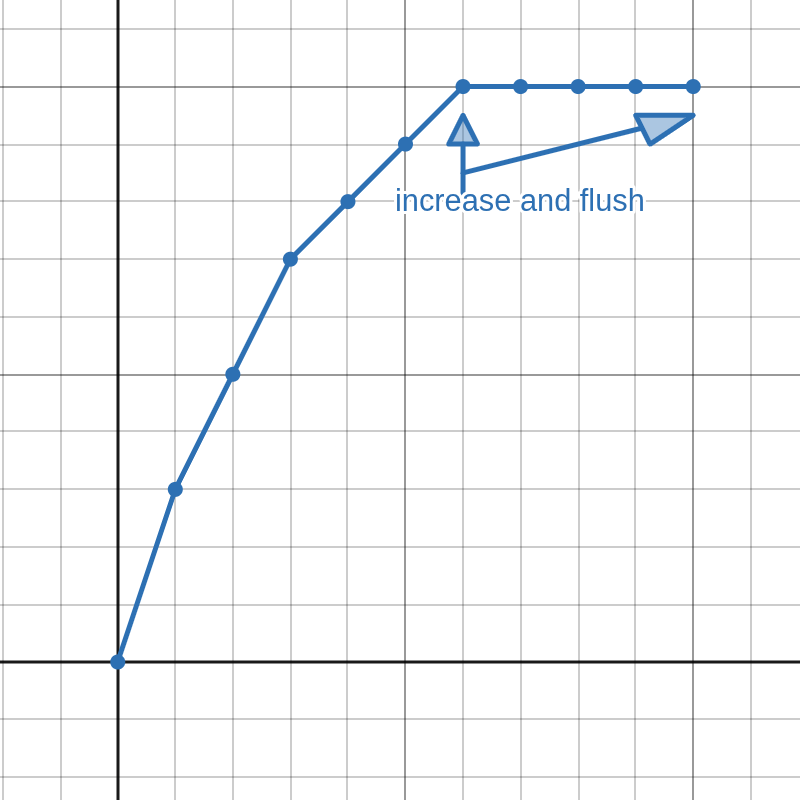
The next few functions can be obtained by incrementing and flushing the next digits on the right by using reasoning from Step 2. The index for flushed digit can be cached to keep track where to flush next. Increment and flush until the digit equals
BASEor until the index equalsBASE.
Since we are conceptually counting numbers here, once a to-be-incremented digit equals
BASE, the digit from the left must be incremented. However, the first derivative is known to be decreasing, we can only increment the leftmost digit of a segment with same derivative—increasing any digit on the right side would increase the derivative, so find where the derivative changes and increment that. Normally when counting, incrementing a digit would zero all digits on the right side, but this would break monotonicity, so flush instead.
 (a) Cannot increment this one.
(a) Cannot increment this one.
 (b) Have to increment from the left and flush.
(b) Have to increment from the left and flush.
If the first digit equals
BASE, then we are done. Otherwise, go to Step 2.
Code for generating next function in sequence is called f_next(), which can be found in src/shared.h. It has been verified to find all valid function tables by comparing it's generated sequence of function tables to the sequence of function tables generated by a naïve counter.
The precision of the generated tables is horrific at this point. Not only our lookup table consists of small integers, but the derivative also decreases in discrete steps. As seen in Figure 6, This means that the second derivative would consist of large spikes at these steps and zeros otherwise, so we must smooth out the steps.
 (a) Generated arctan
(a) Generated arctan
 (b) Generated derivative
(b) Generated derivative
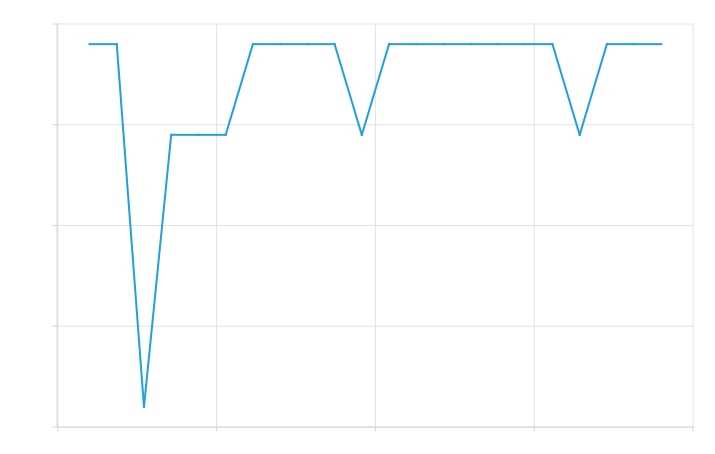 (c) Generated second derivative
(c) Generated second derivative
Filter
To smooth out the discrete steps, we had to process the clipper lookup table with a smoothing filter. Before filtering, it is important to have the duplication of the positive side to the negative side done. The filtering had three major requirements:
Good step response: the filter should preserve the clippers overall shape (no ringing).
Good stopband attenuation: the derivatives are extremely sensitive to high frequencies.
Zero-phase:
f[0]must stay at zero. This is only possible after duplicating positive side to negative side.
The first two requirements are somewhat conflicting, but a good compromise was found by using three single pole IIR low-pass filters in series with a IIR coefficients
Any low-pass filter will ruin the first samples it processes, so we had to extrapolate our clippers. We chose to do quadratic extrapolation by finding the first and second differing samples from the edges to estimate first and second derivatives at the edges. This implicitly assumes non-zero first derivative, which unfortunately slightly reduced the generators capability to generate bounded clippers (a flat tail extrapolated to non-flat), but it considerably improved it's capability to generate converging and diverging clippers, so it was worth it.
Figure 7 shows the generated unnormalized clipper in
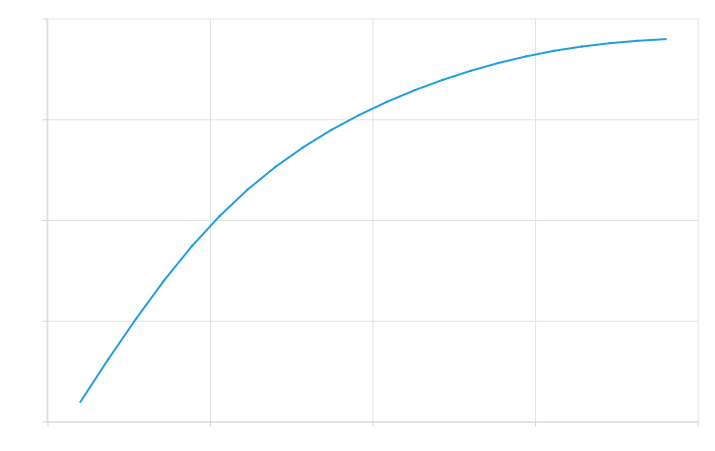 (a) Generated arctan
(a) Generated arctan
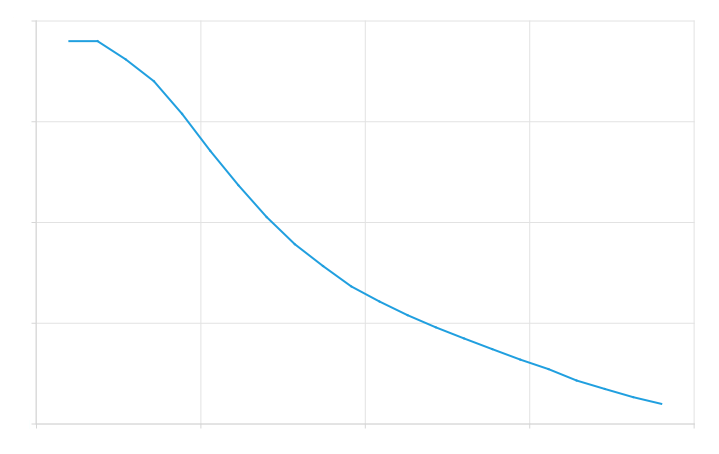 (b) Generated derivative
(b) Generated derivative
 (c) Generated second derivative
(c) Generated second derivative
Lookups
Input gain normalization uses
Normalization
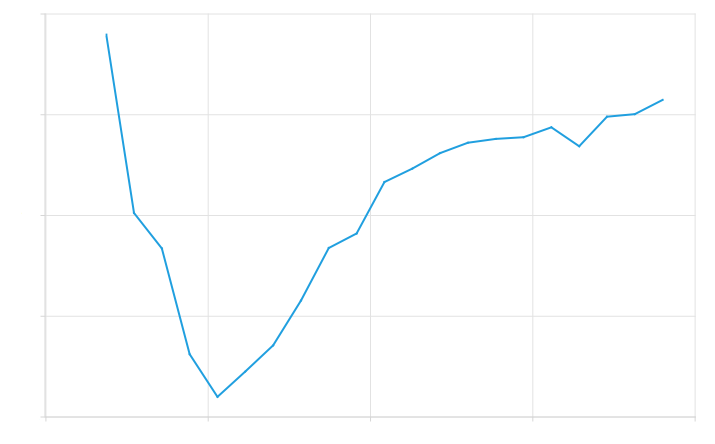
Input gain was normalized by finding the input gain value that matched our normalized THD value. We chose a value such that
To find the good initial guesses for secant method, we plotted THD as a function of input gain (Figure 8) for a large number of generated clipper functions. The first guess would be simply the input gain that on average gives the normalized result, which we visually, from Figure 8 (b), concluded to be 0.6. For second guess, we noted that input gain cannot be negative because THD is calculated from squared coefficients. This allowed us to find a minimum point where
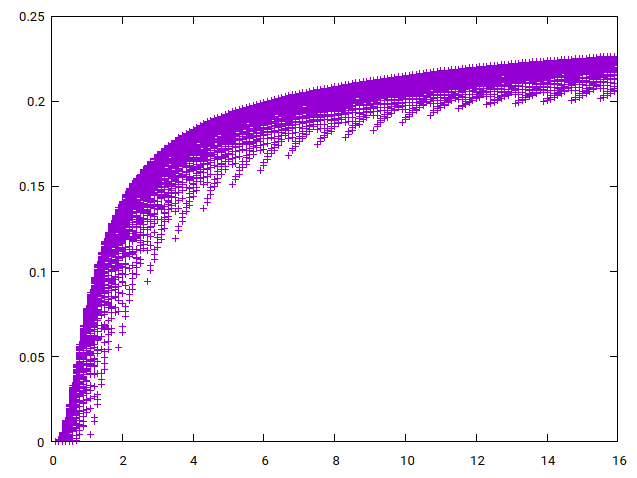 (a) Zoomed out
(a) Zoomed out
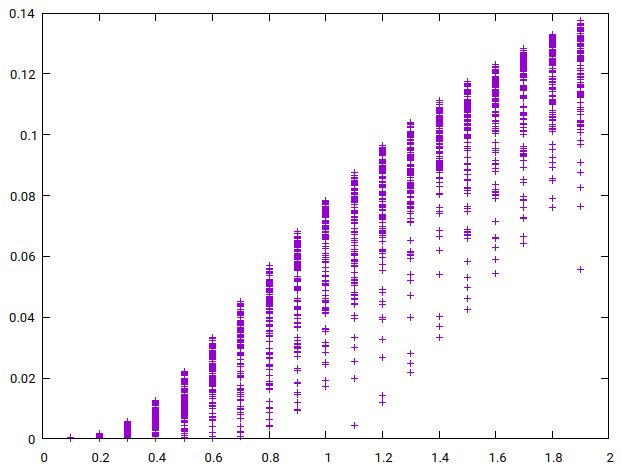 (b) Zoomed in
(b) Zoomed in
Output gain normalization was trivial using rms and ignores DC since symmetric clippers does not produce DC.
The filtered generator was tested by testing if it actually finds a diverging clipper, converging clipper, and a bounded clipper by finding the generated normalized functions with minimal absolute differences from the three functions in BASE.
Hardness
The final part was to compute the second derivative of the positive side using second finite difference of the clipper and find it's minimum (the second derivatives of the positive side are negative) value. It is important to not compute the second derivative from normalized lookups using
Results
For
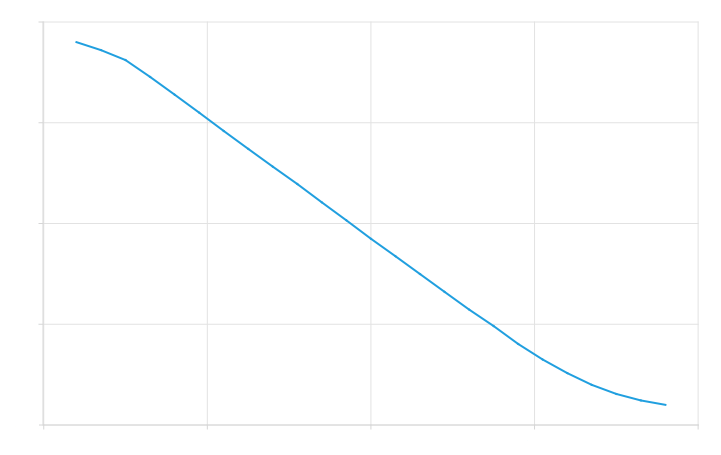
Hard coded Blunter's precise softness was measured to be approximately 0.405966, which is considerably higher than what was measured from the generated function. This is expected: our generator generated the functions based on low precision discrete derivatives and second derivatives. Even after filtering, these discrete steps would still show in the generated function as spikes, as seen before in Figure 6 and Figure 7. However, since Blunter has a constant second derivative, we expect to have many spikes in the second derivative that are spread out as evenly as possible. Figure 9 (c) shows the second derivative of the generated function, where you can clearly see these spikes. While they are indeed very evenly spread out, they will nonetheless increase the measured hardness.
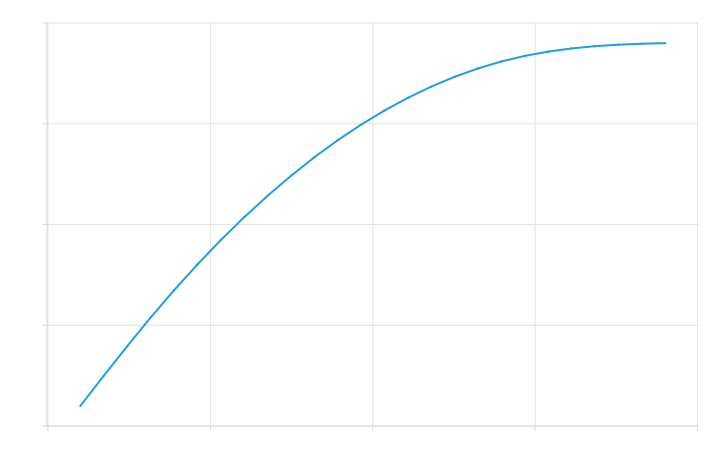 (a) Softest generated clipper
(a) Softest generated clipper
 (b) Generated derivative
(b) Generated derivative
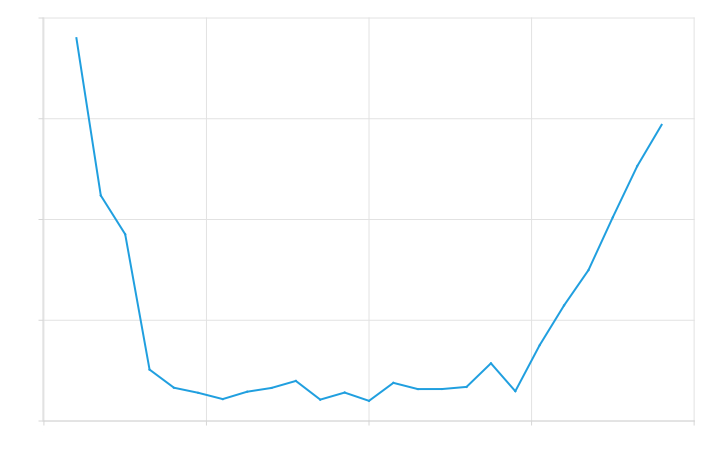 (c) Generated second derivative
(c) Generated second derivative
It is also worth noting that our generator made the function symmetric by fixing the zeroth element to zero and mirroring the function. This always gives zero second difference at
Comparing Hardness to WTHD Hardness
We can modify the previously described experiment to find the minimum WTHD hardness. Generating the functions, filtering them, and obtaining gain normalization values work the same, although output normalization can be ignored. However, to find how the hardness changes, we must repeatedly compute the Fourier series to obtain WTHD
We estimated the derivative of HFC by incrementing BASE to 80.
We also wrote another program that compares how the second derivative based hardness relates to WTHD hardness. This was to make sure that these significantly different definitions of hardness do indeed measure roughly the same thing. It must be noted that the definitions are quite different, so some discrepancy is expected.
Results
A total of 123 223 638 functions were analyzed. The softest function was found at index 3 235 483 with a WTHD hardness of 0.288513. Again, this function was compared with the Blunter. Now the mean of the absolute differences between these functions was 0.0196245, which is 1.57308 % relative to normalized Blunter's highest value, so even with this very different definition of hardness, we still found the softest to be remarkably close to the Blunter.
The program comparing the two different hardness definitions generated the plots seen in Figure 10. The first scatter plot (a) shows WTHD hardness versus hardness for every fourth generated clippers in
The plot in Figure 10 (b) shows WTHD softness against softness for one hundred quadratic soft clippers
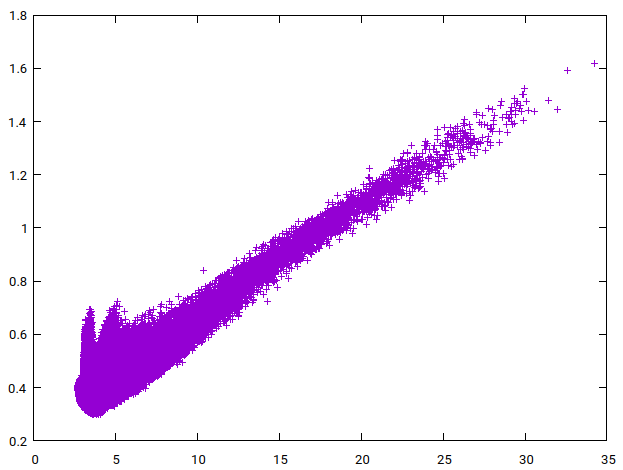 (a) WTHD hardness vs hardness for practically all clippers
(a) WTHD hardness vs hardness for practically all clippers
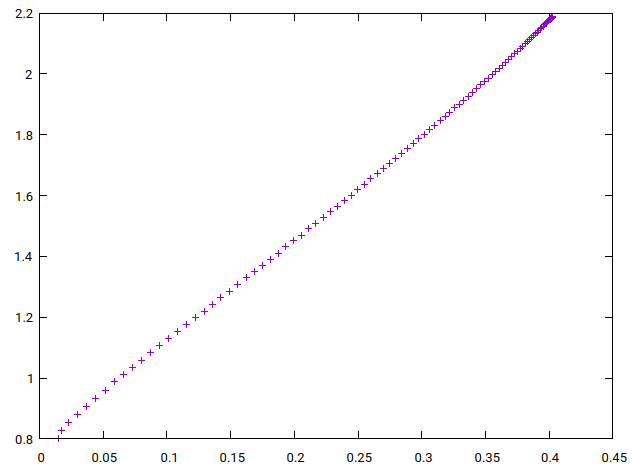 (b) WTHD softness vs softness for quadratic soft clippers with varying knee size
(b) WTHD softness vs softness for quadratic soft clippers with varying knee size
Future Work
While it is expected that the constant second derivative makes the Blunter the softest for all THD normalization values below ours, our experiment only showed that this is the case in the upper limit. It is also expected that the Blunter is the softest clipper when including asymmetric clippers (if it is the softest on one side, why would the other one be any different?), but again, our experiment ignored those to keep computation times sensible. More experiments with different THD normalization values and asymmetric clippers are needed.
We justified the simplification of simply using
Before implementing the main experiment, we did some rough subjective tests to see if it is worth to conduct the study to begin with. We found that the second derivative is potentially audible, so we moved further with the study. However, those preliminary tests were not rigorous at all, they were only conducted to make sure that there is anything meaningful to be studied in softness to begin with. This is why these preliminary tests were not discussed in this study. Much more rigorous subjective tests are needed to confirm if either, both, or neither softness definitions actually matches perceived softness in any way.
Conclusion
We presented a method to quantify and analyze clipping softness to address the lack of work that solely focus on clipping softness. We defined clipping hardness and softness mathematically and used the definition to analyze hard clipper and verified that it has zero softness following intuition. We then discussed how input and output gains are normalized in detail to enable meaningful comparisons of clippers. We also presented the Blunter, a quadratic soft clipper, which we claimed to be the softest clipper given our model. The claim was backed with an experiment that showed that if we generate all potential clippers and find the softest one, the generated softest clipper will in fact be the Blunter. Finally, we showed that hardness is related to WTHD hardness.
References
Lauri Lorenzo Fiestas, March 2026